AI INDEPENDENCE
Data boundary control means sensitive work follows policy before it reaches a model.
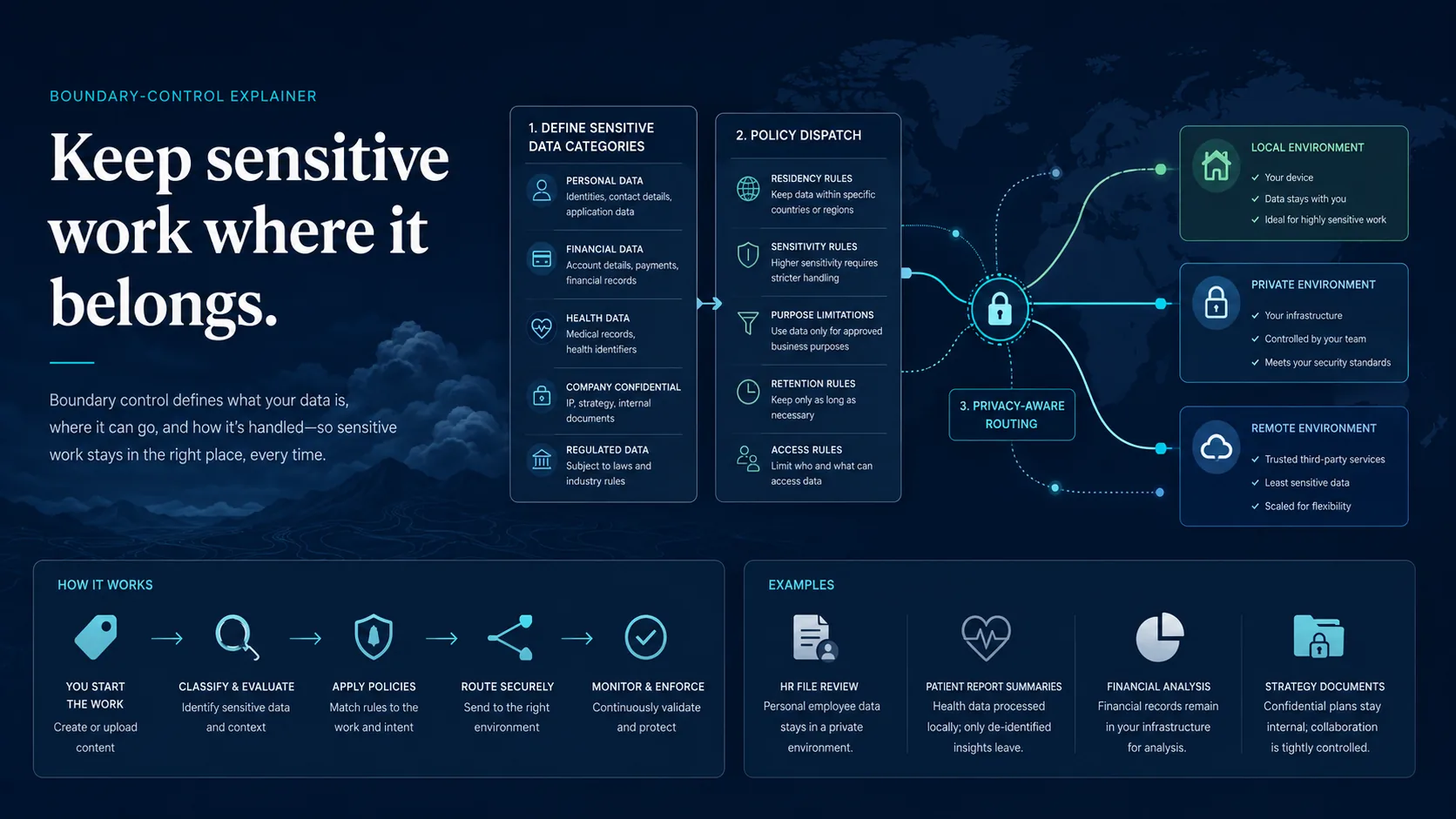
Data boundary control is the ability to decide where AI work is allowed to go, based on the sensitivity of the data, before that work reaches a model, tool, or vendor environment.
Privacy is not a slogan. It is a routing and data-boundary decision.
Not all AI work carries the same risk
A public drafting request and a client contract review should not follow the same path. Blanket rules fail in both directions. Ban everything and people route around you. Allow everything and sensitive data reaches the wrong environment.
The better model is policy-aware dispatch: classify the work, then route it according to clear rules.
How data boundary control works in RouteFreely
RouteFreely is designed to classify requests by sensitivity and route them accordingly. Several capabilities support this, and readiness varies, so we describe them honestly.
Local-only routing keeps requests classified as sensitive inside approved private or local environments. Remote-allowed routing lets lower-risk work use external models when that is acceptable. Privacy classes and per-virtual-model privacy behavior let different routes carry different rules.
The privacy pipeline is designed to detect, classify, redact, and anonymize sensitive information before dispatch. This is a major strategic direction. Detection, redaction, anonymization, and local-only routing are control mechanisms, not guarantees of total privacy, and parts of the pipeline are planned or partially implemented rather than fully complete. We describe them as designed for and in progress, not finished.
MCP access control governs which users and groups can reach which external tools, so a sensitive system is not exposed to everyone. In ChatFreely, domain isolation for retrieval is designed to keep accounting, HR, legal, and engineering knowledge separated by business domain, with RAG enforcement planned rather than shipped in the first wave.


Redaction is a control, not a cure
In some cases, sensitive fields can be removed or masked before a request leaves the boundary. This is useful. It is not a universal solution, and it should be treated as one control among several, not as proof that data is fully protected.
Client proposal
A generic proposal outline can use a standard route. Client pricing, contract history, and private strategy can require a restricted route or human review.
Engineering review
Public code examples may be low risk. Proprietary source code can follow a stricter model and tool policy.
What we do not claim
We do not claim total privacy, zero risk, or complete protection. ThinkFreely helps reduce unmanaged exposure by putting classification, routing, and access policy in front of AI usage. It is a way to manage risk deliberately, not to eliminate it.
Operating checks for data boundaries
Key operating checks:
- which data categories may appear in the workflow
- which environments are approved for sensitive work
- when redaction, local handling, or review is required
- how exceptions are logged and escalated
- whether users understand the boundary before they use AI
Sensitive work should follow clear policy before it reaches an AI model.
